Btrfs 💾
Btrfs stands for B-tree File System, not "Better File System," though it’s easy to see why people might think that. I believe Btrfs is the future for both small and large-scale projects, as it reduces the need for manual and automated maintenance, while simplifying backup and restoration processes.
This article aims to shed light on the history and motivation behind creating Btrfs, its core functionality, and the standout features that set it apart from the competition.
History
Motivation
The idea for Btrfs was first proposed by IBM researcher and bioinformatician Ohad Rodeh at a USENIX conference in 2007. The goal was to develop a copy-on-write (COW)-friendly B-tree algorithm, which would allow for efficient data storage and retrieval without the overhead typical of other file systems.
As Valerie Aurora explained:
"To start with, B-trees in their native form are wildly incompatible with COW. The leaves of the tree are linked together, so when the location of one leaf changes (via a write—which implies a copy to a new block), the link in the adjacent leaf changes, which triggers another copy-on-write and location change, which changes the link in the next leaf... The result is that the entire B-tree, from top to bottom, has to be rewritten every time one leaf is changed."
– Valerie Aurora1
Chris Mason, a core developer of the Reiser Filesystem, liked the idea and saw an opportunity to move beyond Reiser, which used B-trees but wasn’t optimized for COW. Mason brought the idea to his new job at Oracle, where development of Btrfs began in earnest.
"I started Btrfs soon after joining Oracle. I had a unique opportunity to take a detailed look at the features missing from Linux, and felt that Btrfs was the best way to solve them."
– Chris Mason2
In collaboration with Oracle colleague Zach Brown, they drafted the initial version of Btrfs.
Rapid Development ⏱️
Thanks to corporate backing and a team of experienced developers, Btrfs moved through an aggressive development cycle. Within two years of the technical proposal, a working 1.0 version of Btrfs was released in late 2008.
Shortly after its introduction, Btrfs was merged into the mainline Linux kernel. Despite the conservative nature of file system adoption—where admins, systems engineers, and software engineers prefer proven, stable systems—Btrfs quickly gained traction.
In 2015, SUSE Linux Enterprise Server (SLES) became the first major Linux distribution to adopt Btrfs as its default file system, citing it as the future of Linux storage solutions.
Enterprise Adoption 📊
Today, Btrfs is the default file system for several major enterprise Linux distributions, including SUSE, Fujitsu Linux, Ubuntu, Oracle Linux, and popular user distributions like Fedora, Arch, and Gentoo.
In fact, Meta (formerly Facebook) uses Btrfs to manage their large, dynamic data sets. According to core developer Josef Bacik, using Btrfs at Meta has significantly reduced access times and contributed to cost reductions in production environments.3
How Btrfs Works ⚙️
The B-Tree+ Algorithm 🌳
At its core, Btrfs relies on a B-tree, a type of data structure designed to organize and store data efficiently.
Here is a basic diagram of a B-tree, though in file systems, it gets more complex:
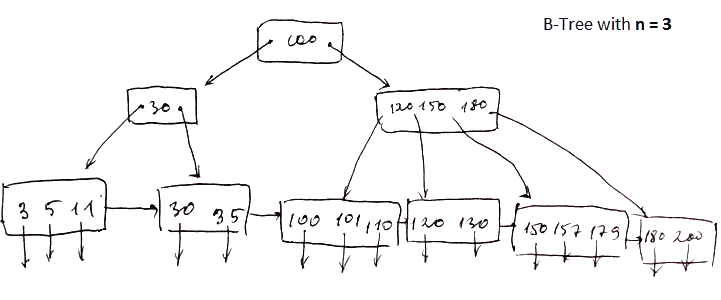
A B-tree consists of nodes and links (sometimes referred to as keys and pointers or leaves and branches), which drastically reduce seek time. This ensures that, no matter how much data you store, finding the right file is quick and doesn’t require searching through everything.
The root node is a type of index stored in a fixed location on the disk. It serves as the starting point for a rapid search called fanning out.
This structure reduces disk access time and, in turn, improves overall system efficiency. The relationship between the depth of nodes and the breadth of data is known as the fan-out factor. Tuning this ratio can either speed up searches (with a wider spread) or reduce write size for smaller segments.
Copy-on-Write (COW) 🐄
Copy-on-Write (COW) is a method where data and metadata are not overwritten in place. Instead, they are copied to a new location before the update is finalized. Btrfs employs COW in conjunction with its B-tree algorithm to maintain data integrity.
Btrfs also uses delayed allocation, where metadata is updated first, linking it to new data before the actual data is copied Persistant Pre Allocation to a new location. This delay allows the file system to organize sector placement called Extent Base Allocation and optimize metadata before the actual write Multi-Block Allocation, reducing unnecessary reads and writes.
This delayed allocation process supports wear leveling (also known as TRIM) on SSDs, where data is written to new sectors to avoid repeatedly writing to the same location, thus extending the lifespan of the drive.
Snapshots 📸
Snapshots are one of Btrfs's standout features. They use COW to create lightweight, efficient snapshots of data at any given time.
Unlike traditional Linux filesystems, which only allow snapshots of logical volumes, Btrfs can snapshot both volumes and subvolumes. This means that the entire data set—down to the subvolume level—can be efficiently snapshotted. Snapshots in Btrfs do not require duplication of data, only tracking changes made after the snapshot was taken.
Cloning 🐑🐑
Cloning in Btrfs allows you to create writeable copies of subvolumes or snapshots, which share the same data blocks until changes are made. Unlike traditional file copying, cloning doesn't duplicate the original data, making it fast and storage-efficient. When modifications are made, only the changed blocks are copied, leaving the rest shared between the clone and the original.
This makes cloning in Btrfs ideal for use cases where multiple environments or datasets need to be derived from the same base system, without significant storage overhead.
Dynamic Online Storage 📈📉
Btrfs allows you to manage storage pools dynamically with online resizing and device management, meaning that you can expand and shrink file systems while they are mounted and in use. This flexibility helps reduce downtime and allows systems to scale easily with growing storage needs.
Expanding Disk Pools 🏊♂️🏊♂️🏊♂️
You can add new disks to a Btrfs file system without stopping the system. With a simple command, Btrfs integrates the new storage into the existing pool, redistributing data across devices if necessary. This feature makes Btrfs highly scalable, especially in environments where storage demands can grow unpredictably.
Resizeable 📏
Btrfs volumes can be expanded or shrunk online, without unmounting the file system. Expanding is as simple as adding more storage, while shrinking requires no special process apart from the resizing command. This dynamic resizing means you can adjust the size of your file system to suit your current storage needs.
Self-Healing ❤️🩹
Btrfs provides self-healing capabilities when used in a redundant RAID setup. Through data and metadata checksumming, Btrfs can detect corrupted blocks and automatically fix them using redundant copies of the data. This ensures data integrity without user intervention, particularly useful for critical data environments.
Compression 🪗
Btrfs supports transparent compression, which means files can be compressed as they are written to disk, saving space without requiring manual compression. It supports multiple algorithms like LZO, Zlib, and Zstandard (ZSTD), each with different balances of speed and compression ratio. This feature helps save storage space and can improve performance, especially when working with large datasets.
Technical Feature List: 🔍
- Journaling: Keeps track of changes before they are committed, helping with data recovery in case of a crash.
- Extent Base Allocation: Allocates large, contiguous blocks of storage to reduce fragmentation.
- Persistent Pre-allocation: Reserves space for a file at creation to prevent fragmentation and improve performance.
- Delayed Allocation: Delays the allocation of disk space until data is written, optimizing space management.
- Multi-block Allocation: Allocates multiple blocks at once to increase efficiency, especially for large files.
- Stripe-aware Allocation: Optimizes block allocation for RAID systems by aligning data with RAID stripes.
- Resizeable with resize2fs: Can be resized (grown or shrunk) using the resize2fs tool.
- B-tree Balancing Algorithm - Different from XFS (COW B Tree): Uses a specific B-tree balancing algorithm for efficient file system organization and copy-on-write operations.
- Copy-on-Write (COW): Writes modified data to new locations rather than overwriting existing data, preventing data corruption.
- Snapshots and Clones: Creates point-in-time copies of data (snapshots) and allows for duplication (clones) without full data replication.
- Built-in RAID Support: Provides native support for RAID configurations, improving data redundancy and performance.
- Data and Metadata Checksumming: Ensures data integrity by verifying both data and metadata through checksums.
- Self-Healing: Automatically repairs corrupted data using mirrored or parity blocks in RAID configurations.
- Dynamic Subvolumes: Supports the creation of isolated subvolumes within the same file system for better data management.
- Online Resizing: Allows the file system to be resized while it's still mounted and in use.
- Compression (LZO, ZLIB, ZSTD): Offers various compression algorithms to reduce storage space usage.
- Deduplication: Eliminates duplicate copies of repeating data to save space.
Core Commands 🪨
mkfs.btrfs
Creates a new Btrfs file system on a specified device or partition.
btrfs subvolume create
Creates a new subvolume within an existing Btrfs file system.
btrfs subvolume delete
Deletes a specified subvolume from the Btrfs file system.
btrfs subvolume list
Lists all subvolumes within a Btrfs file system.
btrfs filesystem show
Displays detailed information about the Btrfs file systems on all mounted devices.
btrfs filesystem df
Shows disk space usage, including metadata and data, for a Btrfs file system.
btrfs balance start
Begins a balancing operation to redistribute data and metadata across the Btrfs file system.
btrfs balance cancel
Cancels an ongoing balancing operation.
btrfs scrub start
Initiates a scrub operation to verify data integrity on a Btrfs file system.
btrfs scrub status
Shows the status of an ongoing scrub operation.
btrfs device add
Adds a new device to an existing Btrfs file system, allowing for dynamic storage expansion.
btrfs device delete
Removes a specified device from a Btrfs file system.
btrfs device stats
Displays statistics and error information about devices in a Btrfs file system.
btrfs check
Checks the integrity of a Btrfs file system, often used for troubleshooting.
btrfs rescue chunk-recover
Attempts to recover data chunks from a damaged Btrfs file system.
btrfs filesystem resize
Resizes a Btrfs file system, either expanding or shrinking it dynamically.
btrfs snapshot
Creates a read-only or read-write snapshot of a subvolume or file system.
btrfs property set
Modifies properties of a Btrfs file system or its subvolumes (e.g., enabling compression).
btrfs quota enable
Enables quota enforcement on a Btrfs file system to limit space usage.
btrfs quota rescan
Rescans the file system to enforce or update quota limits.
Conclusion
Well I hope that has opened your eyes to the benefits of Btrfs. Researching for this article has helped me to learn some more about the subject. If will definitely add to the article as I learn more about the subject, so consider this evergreen information 🌲
Helpful Links ⛓️
https://en.wikipedia.org/wiki/Btrfs https://docs.kernel.org/filesystems/btrfs.html Footnotes
The above quote is excerpted from Valerie Aurora Article lwn.net, 2009.
Chris Mason Interview during LF Collaboration Summit, 2009.
The above reference is to the first proposal for the Btrfs file system Technical Proposal during Gopherfest, Tues, June 12th, 2017.
Btrfs at Scale: How Meta Depends on Btrfs for our entire infrastructure. Presented by Josef Bacik of Meta Presentation Open Source Summit, 2023.